JS 基础
JS 数组去重
利用集合
1 | const arr = [1, 1, 2, 2, 3, 3] |
filter + indexOf
indexOf 返回的始终是元素第一次出现的位置。
1 | const arr = [1, 1, 2, 2, 3, 3] |
JS 垃圾回收机制(GC)
概述
垃圾回收机制(Garbage Collection))简称 GC,所谓垃圾回收机制就是清理内存的方式。
垃圾回收机制会定期(周期性)找出那些不再用到的内存(变量),然后释放其内存。不再用到的内存,没有及时释放,就叫做内存泄漏(memory leak)。
在 JS 中,我们创建变量的时候,JS 引擎会自动给对象分配对应的内存空间,不需要我们手动分配。当代码执行完毕的时候,JS 引擎也会自动地将你的程序,所占用的内存清理掉。正是因为有垃圾回收机制,才导致了开发者有着不用关心内存管理的错误感觉。
内存的分配机制
JS 数据类型分为两种:
- 基本数据类型
- 引用数据类型
基本数据类型保存在固定的栈内存中,可以直接访问它的值。
引用数据类型,其引用地址保存在栈内存中,引用所指向的值保存在堆内存中,需要通过引用地址去访问它的值。
存储在栈内存中的基本数据类型的值,可以直接通过操作系统进行处理。
而堆内存中的引用数据类型的值,大小并不确定,因此需要 JS 引擎的垃圾回收机制进行处理。
内存的回收机制
在浏览器的发展历史上对于垃圾回收有两种解决策略:
- 标记清除法
- 从2012年起,所有浏览器都使用了标记清除法。
- 目前主流浏览器都是使用标记清除式的垃圾回收策略,只不过收集的间隔有所不同。
- 引用计数法
- JS引擎很早之前使用过这种策略回收内存。
- 其核心思想为:将不再被引用的对象(零引用)作为垃圾回收,需要提醒的是,这种策略由于存在很多问题,目前逐渐被弃用了。
标记清除算法
当变量进入执行环境时,就将这个变量标记为”进入环境”,从逻辑上讲,永远不能释放进入环境变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为”离开环境”。
1 | function f1(){ |
垃圾回收机制在运行的时候会给存储在内存中的所有变量都加上标记(可以是任何标记方式),然后,它会去除掉处在环境中的变量及被环境中的变量引用的变量(闭包)的标记。而在此之后剩下的带有标记的变量被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后垃圾回收机制到下一个周期运行时,将释放这些变量的内存,回收它们所占用的空间。
通过标记清除之后,剩下没有被释放的对象在内存中的位置是不变的,这就会导致空闲内存是不连续的,这就造成了内存碎片问题。
如果之后需要存储一个新的,需要占据较大连续内存空间的对象的时候,就会造成影响。
标记整理算法
它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存。
引用计数算法
该策略的处理过程如下:
- 当声明一个引用类型并赋值给变量时,这个值的引用次数初始为1
- 如果该值又被赋值给另一个变量,引用次数+1
- 如果该变量被其他值覆盖了,引用次数-1
- 当这个值引用次数变为0时,说明该值不再被引用,垃圾回收器会在运行时清理释放其内存
代码如下:
1 | let a = new Object() // 引用次数初始化为1 |
但是存在一些问题,例如最常见的是循环引用现象:
1 | function fn(){ // fn引用次数为1,因为window.fn = fn,会在window=null即浏览器关闭时回收 |
若是采用标记清除策略则会在 fn 执行完毕后,作用域销毁,将域中的 A 和 B 变量标记为 0以便 GC 回收内存,不会存在这种问题。
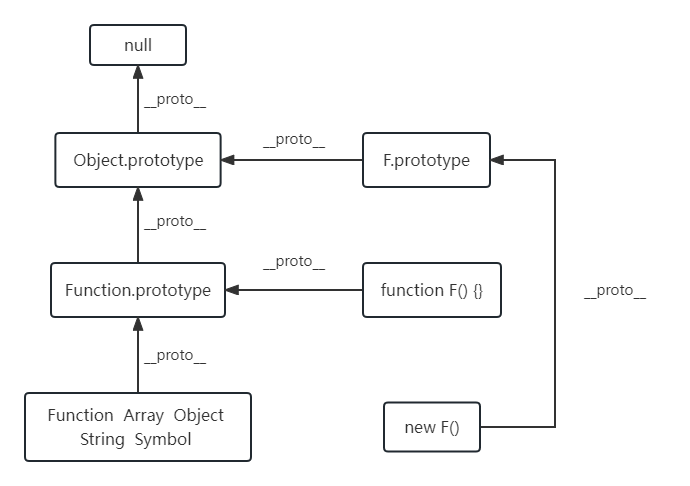
JS 原型链
每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针。那么假如我们让原型对象等于另一个类型的实例,结果会怎样?显然,此时的原型对象将包含一个指向另一个原型的指针,相应地,另一个原型中也包含着一个指向另一个构造函数的指针。假如另一个原型又是另一个类型的实例,那么上述关系依然成立。如此层层递进,就构成了实例与原型的链条。
prototype 与 proto
prototype (原型)是构造函数才有的,因为 js 的构造函数和一般 function 没有本质区别,所以只有 function 有 prototype 这一属性。
__proto__ 属性任何对象都有,其指向对象的原型(prototype)。
1 | function F() {} |
函数对象
凡是通过 new Function() 创建的都是函数对象。
一般来说,对象只有 __proto__ 属性,但是函数对象既有 __proto__ 属性,也有 prototype 属性。
函数对象有 Function、Object、Array、Date、String、自定义函数。
1 | console.log(typeof Object); //function |
原型对象
原型对象即 XXX.prototype。
原型对象是包含特定类型的所有实例共享的属性和方法。原型对象的好处是,可以让所有实例对象共享它所包含的属性和方法。
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
1 | function F() {} |
一般来说,原型对象的类型都是 object,但是 Function.prototype 是个例外,它是原型对象,却又是函数对象,作为一个函数对象,它又没有 prototype 属性。
1 | console.log(typeof Function.prototype) // 特殊 function |
图解
箭头函数和普通函数区别
箭头函数全都是匿名函数,普通函数可以有匿名函数,也可以有具名函数;
箭头函数不能用于构造函数;
箭头函数没有 arguments 对象;
箭头函数没有原型对象;
this 指向不同。
JS 继承方式
原型链继承
让一个构造函数的原型是另一个类型的实例,那么这个构造函数 new 出来的实例就具有该实例的属性。
1 | function Parent() { |
缺点:对象实例共享所有继承的属性和方法。不能传递参数。
构造函数继承
1 | function Parent(name, age) { |
使用 apply() 或 call() 方法在子类构造函数中调用父类构造函数,同时将 this 指向 Son。
优点:解决了原型链继承对象实例共享所有继承的属性和方法以及不能传递参数的问题。
缺点:通过原型添加的属性和方法无法继承。
组合继承
所谓组合继承即将原型链继承和构造函数继承组合到一起。
使用原型链实现对原型属性和方法的继承,通过借用构造函数来实现对实例属性的继承。
1 | function Parent(name, age) { |
优点:解决了原型链继承和构造函数继承造成的影响。
缺点:调用两次父类构造函数。
原型继承
Object.create()方法用于创建一个新对象,使用现有的对象来作为新创建对象的原型(prototype)。
1 | const obj = { |
1 | function Parent(name, age) { |
缺点:属性中引用类型的值会在对象间共享;子类实例不能向父类传参;只能继承原型上的的属性和方法。
寄生组合式继承
1 | function Parent(name, age) { |
JS 判断数据类型方法
使用 typeof
使用 typeof 能够判断出的数据类型有:
string
number
boolean
sysmbol
undefined
function
object
基本数据类型中除了 null 都能直接判断出来。
1 | typeof null // object |
引用数据类型只能判断出 function 和 object。
1 | typeof [1, 2, 3] // object |
object.prototype.toString.call()
Object.prototype.toString.call() 将要检查的对象作为第一个参数传递,返回 "[object Type]",这里的 Type 就是参数的类型。
1 | Object.prototype.toString.call([]); // "[object Array]" |
手写 bind
1 | Function.prototype.bind = function() { |
JS new 一个对象的过程
创建一个空对象;
将该对象连接到对应类的原型;
执行类的构造函数,并将 this 指向该对象,使其拥有类的属性和方法;
返回该对象。
1 | function myNew() { |
柯里化
概念
柯里化,用一句话解释就是,把一个多参数的函数转化为单参数函数的方法。
当一个函数有多个参数的时候先传递一部分参数调用它(这部分参数以后永远不变),然后返回一个新的函数接收剩余的参数,最后返回结果。
1 | function plus(x, y){ |
经过柯里化后这个函数变成这样:
1 | function plus(y){ |
作用
惰性求值
柯里化的函数是分步执行的,第一次调用返回的是一个函数,第二次调用的时候才会进行计算。起到延时计算的作用,通过延时计算求值,称之为惰性求值。
动态生成函数
看如下示例:
1 | function log(level) { |
可以看到,如果我们想打印不同级别的日志,且为每条日志固定日志的级别,通过柯里化可以轻松地为当前日志创建便捷函数。
高级柯里化实现
1 | function curry(func) { |
curry 函数创建一个函数,该函数接收一个或多个 func 函数的参数,如果 func 所需要的参数都被提供则执行 func 并返回执行的结果,否则继续返回该函数并等待接收剩余的参数。
1 | function sum(a, b, c) { |
事件的 target 与 currentTarget
event.target 指向触发事件的元素,而 event.currentTarget 则指向事件被绑定的元素。
以点击事件为例,只有被点击的那个目标元素的 event.target 才会等于event.currentTarget。
Web API
Page Visibility API
该 API 可以监听页面是否可见,一般在切换浏览器 Tab 页或将浏览器最大化最小化时触发。
1 | document.addEventListener("visibilitychange", () => {}) |
如果想知道页面具体是隐藏了还是显示了,可以用 document.hidden 来判断。
1 | document.addEventListener("visibilitychange", () => { |
网络状态监控
如果想判断是否有网络,可以使用 navigator.onLine,为 true 则有网,反之没网。
监听网络状态变化:
1 | // 从离线到在线 |
在有网的情况下,想知道网络的一些具体信息可以使用 navigator.connection,它是一个对象,有以下属性:
- downlink:网速,单位是 M\s;
- effectiveType:网络类型,可能值为 “2g”、“3g”、“4g”;
- rtt:网络延迟
其中 effectiveType 是根据 downlink 和 rtt 计算得出的。
监听网络类型的变化:
1 | navigator.connection.addEventListener("change", () => { |
navigator.connection 中的属性发生变化时都可触发。
Web Animation API
Web Animations API 允许同步和定时更改网页的呈现,即 DOM 元素的动画。
其扩展到 Element 接口,使 Element 接口具有以下两个方法:
Element.animate()Element.getAnimations()
Element.animate()
1 | animate(keyframes, options) |
keyframes
关键帧对象数组,关键帧对象类似于 css @keyframes 中的内容:
1 | [ |
键就是 css 属性,值是 number 或 string,如果是 clip-path 这样的属性需写成 clipPath。offset 类似于 @keyframes 的百分比进度,取值为 0.0-1.0,只能递增。不写的话默认时间平均分配。easing 是时间函数。
options
有以下属性:
duration:对应 css 的animation-duration;easing: 对应 css 的animation-timing-function;direction:对应 css 的animation-direction;fill:对应 css 的animation-fill-mode;iterations:对应 css 的animation-iteration-count
https://developer.mozilla.org/zh-CN/docs/Web/API/Element/animate
Element.getAnimations()
返回 Animation 类型的数组,可以清空、暂停动画。
https://developer.mozilla.org/zh-CN/docs/Web/API/Animation
Drag API
可拖拽元素
想要一个元素是可拖拽的,只需添加 draggable 属性即可:
1 | <div draggable="true"></div> |
拖拽事件
ondragstart
由拖拽元素触发。只在拖拽开始时触发一次。
ondragover
由目标元素触发。当拖拽元素在目标元素上方时,该事件会一直触发。
ondragenter
由目标元素触发。当拖拽元素进入目标元素中时触发一次。
ondragleave
由目标元素触发。当拖拽元素离开目标元素中时触发一次。
ondrop
由目标元素触发。当拖拽元素在目标元素中松开鼠标时触发一次。
注意: 像 div、td、tr 等元素默认是不允许别的东西拖拽到其上面的,会导致其不能触发该事件。我们可以在 ondragover 事件中阻止浏览器的默认行为。
1 | box.ondragover = e => { |
拖拽效果
默认情况下,当我们将一个元素拖拽到目标元素上方时,鼠标会出现一个加号,表示复制。它还有一种状态是表示移动,可在拖拽元素的 ondragstart 事件中设置:
1 | box.addEventListener("dragstart", (e) => { |
如果想在将拖拽元素拖拽到目标元素上方时改变目标元素的背景颜色,可以进行如下操作:
1 | container.ondragenter = e => { |
实现拖拽
现在将拖拽元素拖拽到目标元素上方然后松开鼠标时,什么也没有发生。我们期望在松开鼠标时将拖拽元素复制或移动到目标元素中。这就需要我们在 drop 事件中做一些事情。
复制:
1 | let source; |
移动:
1 | let source; |
Clipboard API
该 API 的应用包括阻止用户复制站点内容、在用户复制的内容后面添加一些东西
这个 API 分为两个部分,包括一个对象和一套事件。
对象
对象是 navigator.clipboard,它包含了一些方法:
1 | // 向剪贴板写入一些内容 |
事件
监听复制事件
1 | document.addEventListener("copy", e => { |
监听粘贴事件
当用户在浏览器用户界面发起“粘贴”操作时,会触发 paste 事件。
如果光标位于可编辑的上下文中(例如,在 textarea 或者 contenteditable 属性设置为 true 的元素),则默认操作是将剪贴板的内容插入光标所在位置的文档中。
我们可以获取到要粘贴的内容,分为以下两种情况:
(1)粘贴的内容是文本
1 | document.addEventListener("paste", e => { |
(2)粘贴的内容是文件
1 | document.addEventListener("paste", e => { |
移动端监听 beforeunload 无效问题
有时我们需要在前端做数据持久化存储,比如在页面刷新时将仓库中的数据存到 localStorage 中,在页面加载时再将数据从 localStorage 导入仓库。
之前我们一般会这样做:
1 | window.addEventListener("beforeunload", () => { |
但这样写会出现一个问题:在移动端的某些浏览器上 beforeunload 事件没有被触发。
这时可以用 pagehide 替换 beforeunload。
pagehide 与 pageshow
pageshow事件:这个事件在用户浏览网页时触发,pageshow事件类似于onload事件,onload事件在页面第一次加载时触发,pageshow事件在每次加载页面时触发,即onload事件在页面从浏览器缓存中读取时不触发。pagehide事件:该事件会在用户离开网页时触发。离开网页有多种方式,如点击一个链接、刷新页面、提交表单、关闭浏览器等。pagehide事件有时可以替代unload事件,但unload事件触发后无法缓存页面。